SLOs in Cloud-Native & Distributed Architectures

Published on 26 February 2026 by Zoia Baletska

As organisations scale, their software platforms become increasingly distributed. Services are no longer isolated — they communicate, depend on each other, and often operate across different teams, cloud regions, and technology stacks. While this architecture improves scalability and resilience, it also complicates reliability management.
Service Level Objectives (SLOs) are easy to track in a simple system: uptime, latency, or error rate per service. In distributed, cloud-native architectures, however, SLOs become more complex, requiring careful design, cross-team coordination, and the right tooling to provide meaningful insights.
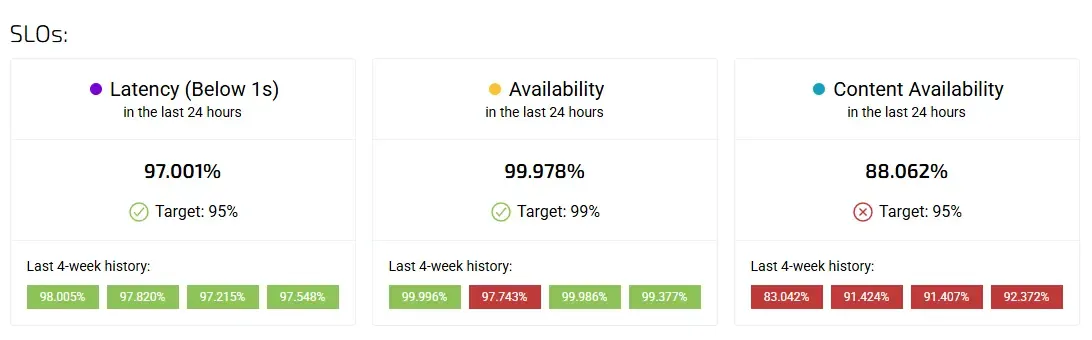
Setting and monitoring SLOs in orchestrated and microservice environments presents unique challenges, from defining ownership to capturing end-to-end reliability across services.
Multi-Service vs Component-Level SLOs
One of the first decisions in a distributed system is what level to measure reliability.
-
Component-level SLOs focus on individual services. For example, a user authentication API might have a 99.9% availability SLO. This approach is easy to define, monitor, and act upon, and it gives engineering teams clear accountability.
-
Multi-service SLOs (or composite SLOs) track reliability across several services that together deliver a user-facing feature. For instance, a checkout experience might depend on the authentication API, payment service, inventory service, and notification service. Even if each component meets its individual SLO, the end-to-end feature may fail if one service underperforms.
Why multi-service SLOs matter: users don’t care if an individual service is up; they care whether their experience works. Measuring SLOs at the feature level provides a more accurate view of real-world reliability, but it introduces complexity:
-
You must propagate error metrics across services.
-
Teams must coordinate on SLO targets that span multiple ownership domains.
-
A single component failure may cascade into a broader impact, requiring careful communication and escalation patterns.
Error Propagation and Reliability Boundaries
In distributed systems, errors don’t stay contained. A failing service can cascade through its dependencies:
-
Slow database queries in a core microservice can increase latency in dependent services.
-
An intermittent timeout in a messaging queue can lead to downstream service retries and amplified error rates.
-
A region-wide outage in one cloud provider may impact multiple services simultaneously.
To manage this, it’s critical to define reliability boundaries:
-
Understand which errors are “acceptable” within the context of the overall system.
-
Identify critical paths where failures must be tightly controlled.
-
Use circuit breakers, bulkheads, and retries to prevent cascading failures from violating SLOs across services.
Distributed SLOs are not just numbers—they are contracts between teams, services, and users, specifying which failures are tolerable and which must trigger immediate remediation.
Tools That Help Correlate Cross-Service SLOs
Tracking multi-service SLOs requires more than a simple dashboard. You need tooling that can:
-
Aggregate and correlate metrics across services, cloud regions, and clusters.
-
Visualise error budget consumption along dependency chains.
-
Highlight leading indicators of potential SLO breaches.
Some approaches include:
-
Distributed tracing (e.g., OpenTelemetry, Jaeger, Zipkin) to track requests across services and spot where latency or errors accumulate.
-
Time-series aggregation tools (Prometheus, Datadog, New Relic) to combine metrics and visualise trends.
-
Composite SLO calculators that automatically propagate component-level SLOs into feature-level or business-level SLOs.
With these tools, teams can move from reactive firefighting to proactive reliability management, ensuring that multi-service systems meet user expectations even as complexity grows.
Best Practices
-
Define SLOs at multiple layers: component-level for engineering ownership, feature-level for user impact.
-
Visualise dependencies: map how errors propagate between services.
-
Use error budgets to drive decisions: multi-service SLO breaches can inform release pacing, prioritisation, and escalation.
-
Automate correlation and alerts: manual tracking is too slow and error-prone.
-
Review and refine SLOs regularly: distributed systems evolve, and SLOs must evolve with them.
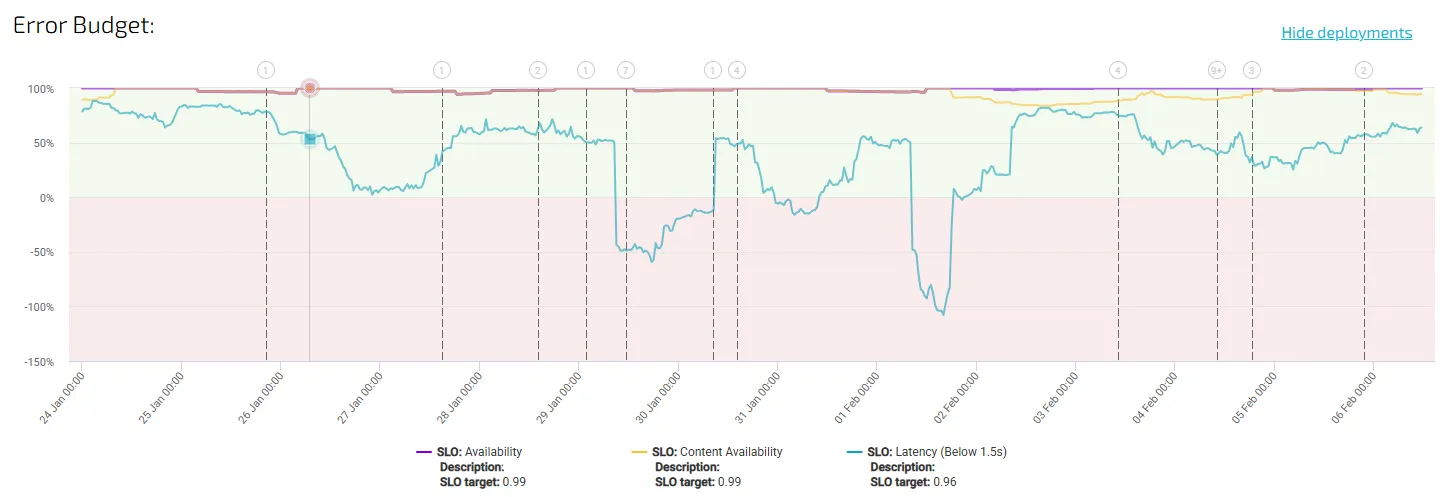
In cloud-native and distributed architectures, SLOs are more than technical metrics — they are a shared language for reliability. By combining component-level insights, multi-service aggregation, and tooling that correlates errors across boundaries, teams can maintain real-world reliability without drowning in data.
Well-designed SLOs help engineering teams prioritise work, protect users, and communicate risk across complex ecosystems. In other words, SLOs are the backbone of reliability at scale.
Set up Error Budgets in 30 Minutes?
Linking your software development to the performance of your production systems has never been easier! Set up Error Budgets in 30 minutes.
Find out here how to do that.





