The Reality Behind AI for Developers: Prompting in Practice

Published on 13 November 2025 by Zoia Baletska

Generative AI is no longer a novelty in development. Tools like Copilot, ChatGPT, and others are deeply embedded in many engineering workflows. But how exactly do developers use them, how reliable are they, and what patterns of prompting and conversation actually help produce useful code? That’s what this recently published paper by Daniel Otten, Trevor Stalnaker, Nathan Wintersgill, Oscar Chaparro & Denys Poshyvanyk set out to discover.
Their study is meaningful because it moves beyond hypothetical “prompt engineering” guides into real-world practices across many developers. It provides concrete data on how developers think, talk to AI, and cope when things go wrong. Below, I summarise what they found—and what we can learn from it.
Study Setup & Methodology
To gather insights, the authors:
-
Surveyed 91 software engineers; 72 of them were active GenAI users (i.e., had experience with prompting)
-
Asked about six core software engineering (SE) tasks: code generation, documentation, debugging, testing, refactoring, and code review
-
Collected both quantitative responses (Likert scales, usage frequency) and open-ended responses (qualitative coding)
-
Analysed how developers structure prompts, how many conversational turns they use, reliability perceptions, and common issues.
Because this is a survey of self-reported behaviour, it has limitations (bias, recall, generalizability). But it still offers one of the strongest empirical baselines we have today on AI usage in developer work.
What They Found — Key Insights
1. AI Use is Widespread, But “Deeper Use” Varies
-
Nearly 91.7% of AI users reported using GenAI for code generation tasks; it's almost the baseline.
-
Other tasks are less common: debugging (47.2%), documentation (44.4%), testing (38.9%), refactoring (31.9%), code review (31.9%)
-
The more tasks a developer uses AI for, the more likely they are to see themselves as proficient. There seems to be a positive feedback loop: using AI more leads to more confidence, which leads to broader use.
Implication: Most teams will start by applying AI to “safe” tasks (like new code generation or documentation). Over time, with experience, some developers will push AI into more nuanced work like debugging or refactoring. But you shouldn’t expect all teams to immediately trust AI in every domain.
2. Prompting is Mostly Iterative, Multi-Turn
-
Developers prefer iterative conversation strategies over "one-shot" prompts. The top strategies: incremental refinement and feedback looping.
-
Rarely do developers complete a meaningful task in a single prompt. Every developer reported needing at least multiple exchanges.
-
Those with the highest self-reported proficiency often use 10+ back-and-forth exchanges — interestingly, lengthier interaction correlates with greater perceived productivity gains.
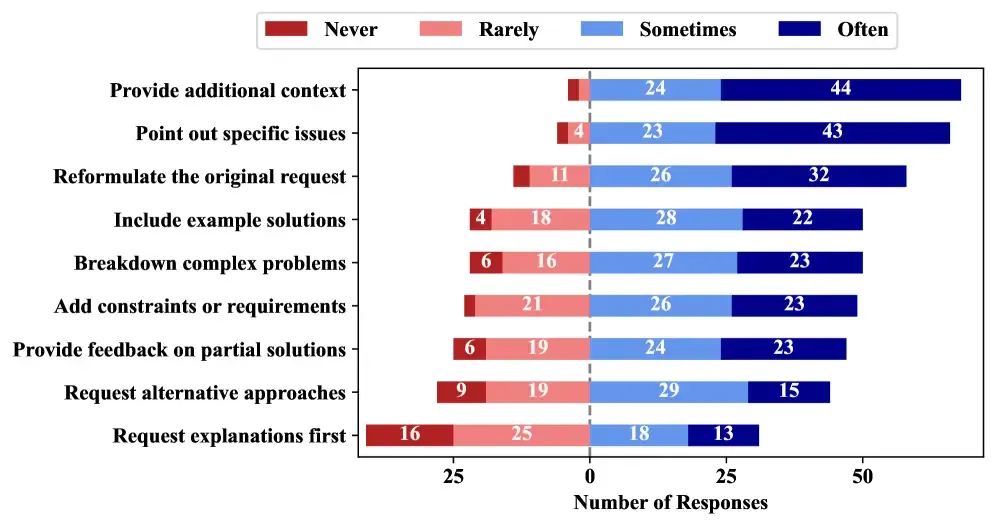
Error handling strategy usage frequency. Source: https://arxiv.org/html/2510.06000v1
Implication: AI tools and integrations should enable easy conversational refinement, the ability to provide corrective feedback, and managing context over multiple prompts. “One big prompt” UX is rarely enough.
3. What Developers Include in Their Prompts & Why
When building prompts across task types, developers tend to include:
-
For code generation: example inputs/outputs, style guidelines, library constraints, and error handling context.
-
For debugging: full error messages, stack traces, logs, attempted fixes, steps-to-reproduce.
-
For testing: code being tested + spec, example test cases, edge cases.
-
For documentation: the code snippet + explanation + target audience + style/format guidance.
Interestingly, developers include things like environment context, performance constraints, version history, or system architecture less often—unless dealing with particularly tricky prompts.
GenAI issue frequency distribution. Source: https://arxiv.org/html/2510.06000v1
Implication: Good prompts are rarely blind. The more contextual, structured, and relevant data you feed in, the better (though balancing verbosity vs clarity is an art). Tools that help structure prompts or auto-generate context wrappers may help adoption.
4. Reliability Varies Strongly by Task Type
-
Documentation tasks are perceived as most reliable. Many developers trust AI to assist or generate docs.
-
Testing/debugging is moderately trusted, but not without risk. Especially debugging: suggested fixes often miss root causes.
-
Complex reasoning tasks (architectural changes, advanced refactoring, non-functional requirements) have the lowest reliability scores.
-
The top failure modes include unintended behaviour changes, incomplete transformations, incorrect compatibility, and AI hallucinations/false positives
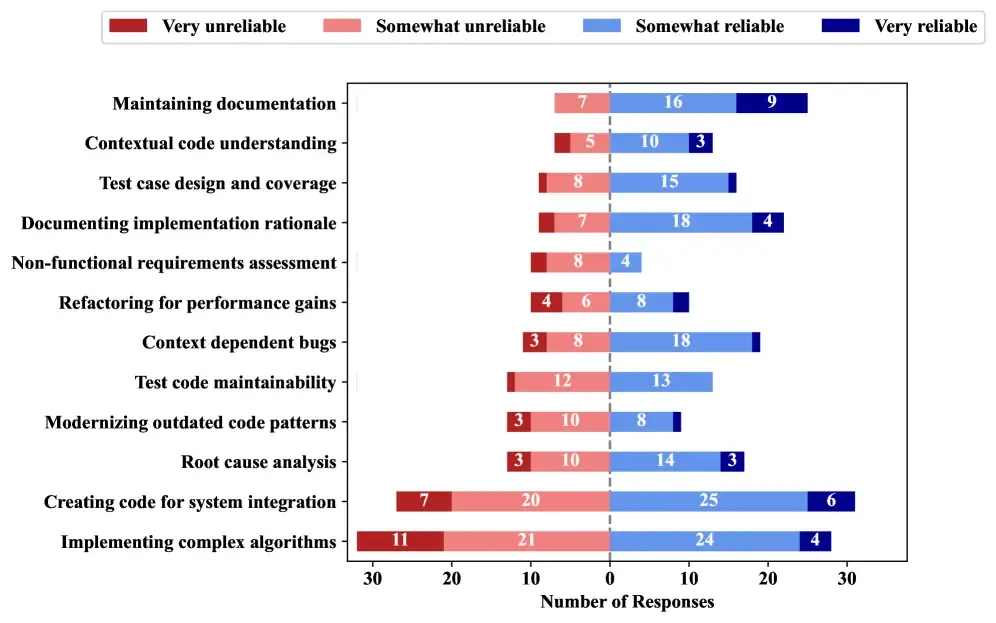
Reliability perceptions of GenAI across tasks. Source: https://arxiv.org/html/2510.06000v1
Implication: Tooling or flows need to proactively flag uncertainty, allow human verification, and scaffold trust when AI is used in higher-risk contexts.
Bringing This into Practice (For Teams & Tools)
Given these findings, here are suggested best practices and product design takes:
-
Start AI adoption with “safer” tasks. Use AI for documentation, boilerplate, or small code generation first (areas with high perceived reliability).
-
Make prompts and context structured. Tools should help build prompts by auto-including project-specific context (imports, architecture, style constraints) rather than requiring users to manually paste everything.
-
Support conversational workflows natively. Allow users to iterate, refine outputs, and send context feedback. Encourage multi-turn interactions rather than monolithic prompts.
-
Confidence indicators & uncertainty visualisation. For AI outputs, show confidence scores or flag ambiguous parts so humans know where to review carefully.
-
Capture and learn from failed responses. When outputs are wrong, track that feedback and adjust prompt templates or model parameters. Tools can surface patterns of recurring errors.
-
Correlate AI usage with developer workflows/metrics. If you have a platform (e.g. Agile Analytics), track where AI is helping, where failures occur, and how that impacts lead time, defect rates, or dev satisfaction.
Final Thoughts
This paper provides one of the most grounded looks yet into how developers actually prompt and talk to AI in their daily workflows. Instead of idealised prompt engineering, we see iterative, conversational, context-rich practices gradually pushing AI deeper into coding, debugging, and review.
For teams and toolmakers, the message is clear: don’t expect magic from one-shot prompts. Enable conversational prompting, provide context scaffolding, manage uncertainty, and keep humans tightly in the loop. That’s how AI can move from novelty into truly reliable engineering collaboration.
Supercharge your Software Delivery!
Implement DevOps with Agile Analytics
Implement Site Reliability with Agile Analytics
Implement Service Level Objectives with Agile Analytics
Implement DORA Metrics with Agile Analytics





