What is Site Reliability Engineering (SRE) and is it different from DevOps

Published on August 2020 by Arjan Franzen

Both DevOps and Site Reliability Engineering (SRE) promise to improve integration between Development and Operations (DevOps) and resiliency in organisations. However, many in our field remain unfamiliar with DevOps and SRE concepts, making it difficult to implement these methods, hire or train for DevOps and SRE roles.
SRE and DevOps are very complementary practices. When implementing both, they accelerate the movement toward continuous delivery. While DevOps brings a systemic perspective to rapidly and consistently deliver customer value, SRE principles enable scale the DevOps practices through principles of software engineering to system management.
“SRE is what happens when you ask a software engineer to design an operations team.” – Benjamin Treynor Sloss Vice President, Engineering, Google
What Is Site Reliability Engineering?
Site reliability engineering (SRE) is a discipline that allows teams to design and operate scalable, resilient systems using a software engineering approach. Key elements of SRE include using software engineering techniques in managing infrastructure, using metrics to track progress and drive innovation, and incentivising a collaborative mindset. SRE is effective at scaling DevOps concepts, as well as managing technical debt and driving further improvements in speed without reducing efficiency. SRE acts as a complement to DevOps practices through managing the risks of rapid change by promoting resilience, accountability and innovation.

Figure 1) Developers and Operators
The different co-dependent cultures (Development, Operations) have 2 seemingly opposite incentive systems. Implementing DevOps forces the organisation to merge these disciplines and have DevOps workflow. When the DevOps culture change is underway SRE will be there to assist and help scale the DevOps culture to be cloud ready. Missing the mark on implementing DevOps will have the Ops team being buried by Manual Tasks (toil).
Key issues that SRE would be well suited to address include, but are not limited to:
Managing Technical debt, prevent operational toil
Rapidly growing organisations or large organisations introducing DevOps, Cloud at a fast pace run the risk of taking on large amounts of technical debt and operational toil. The remediation of which can impede the release of new features and functionality. Site Reliability Engineers (SREs) use a software engineering approach to address defects, reduce toil where necessary and dedicate a significant amount of time to resolving technical debt issues.
Unstable and unreliable systems
High rates of manual input, non-standardised processes and constant firefighting can become a stretch on (Dev)operations staff, as well as lead to further outages and slower deployments. Site Reliability Engineers (SREs) focus on architecting a stable environment that requires as little input as possible from team members to operate in order to limit potential errors. Automated response, stronger monitoring, configuration management, ticketing/logging and other benefits of automation can decrease the mean time to resolution so that when something goes wrong, it’s obvious where and when it happened, as well as how to fix it.
Speed and efficiency improvement
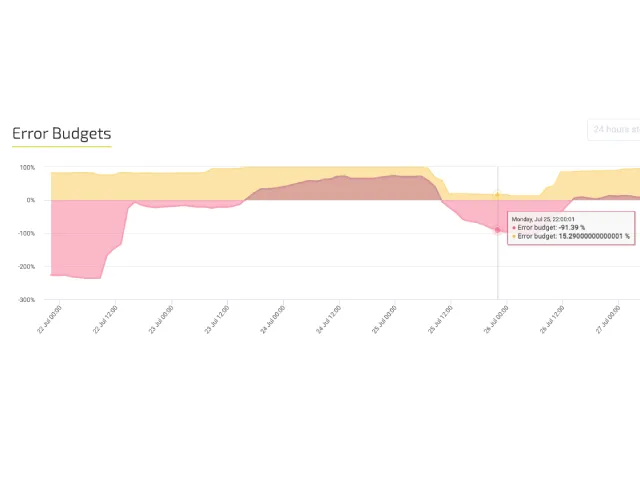
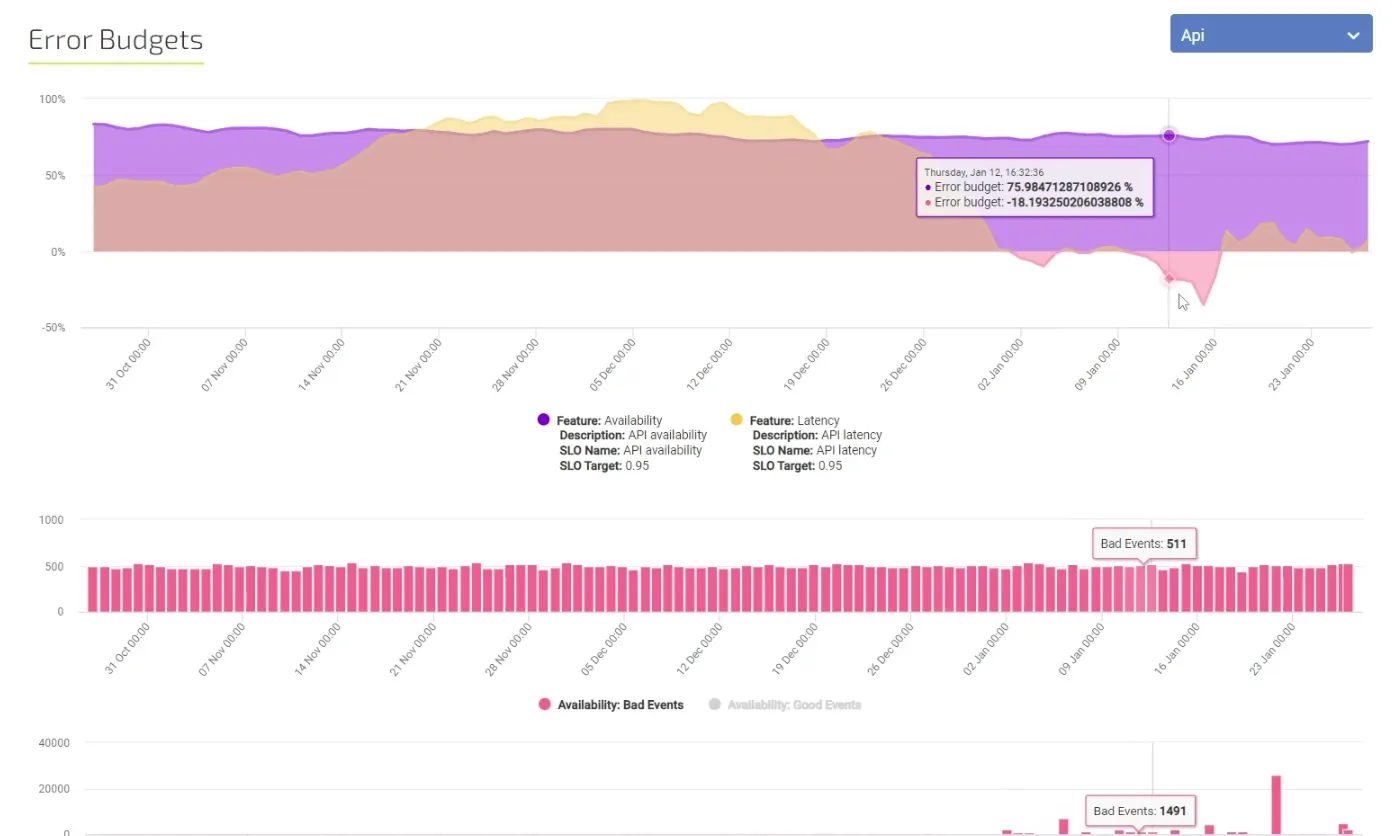
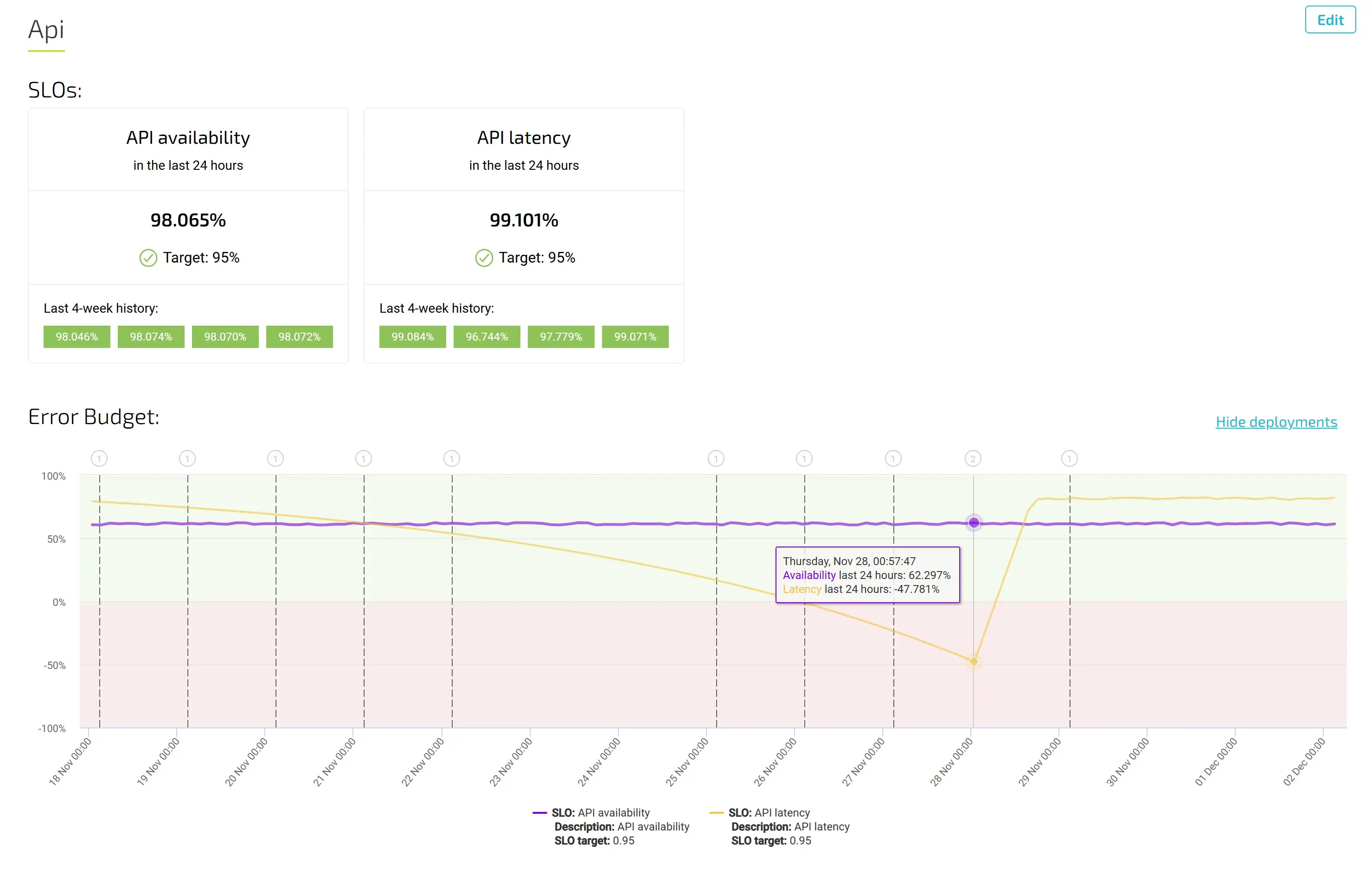
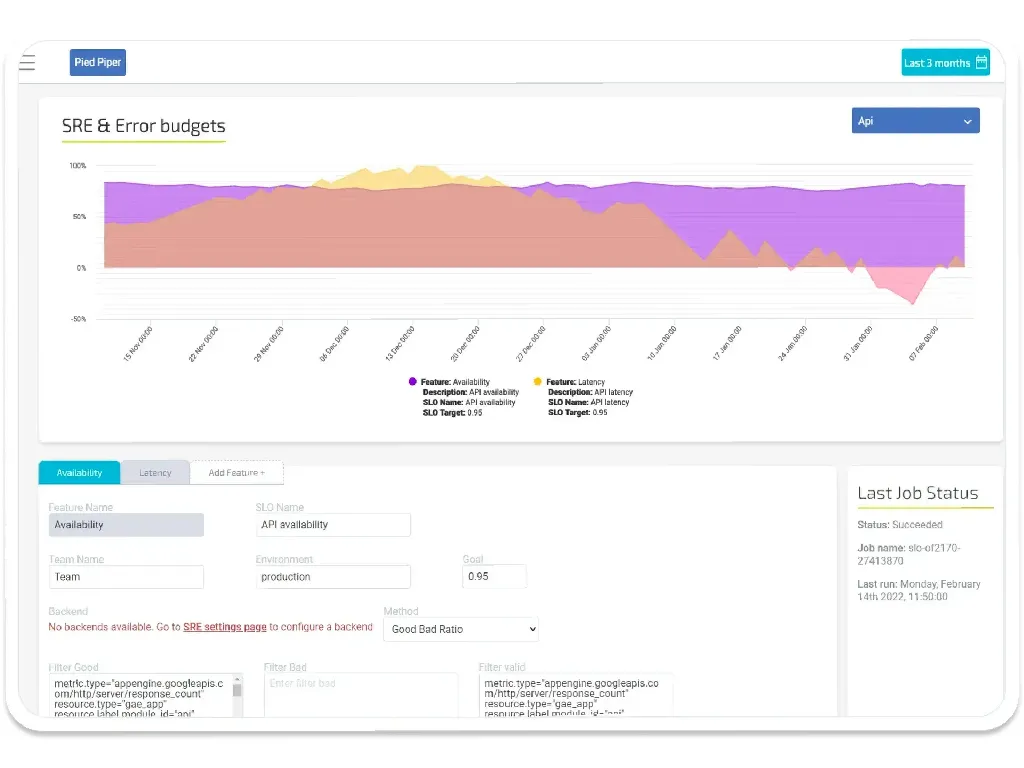
The components of SRE include aspects such as setting SLOs, a blameless root cause culture and using error budgeting and continuous improvement to ensure agility while also promoting faster speed. A fully automated system frees up resources to focus on growth and improving customer experience. And since SREs acknowledge that perfection is unlikely, they learn from their mistakes. The usage of error budgeting allows for introducing innovative solutions without fear that changes are discouraged due to potential limits to availability.
Implement DevOps
Implementing DevOps requires linking the support systems to bring the ‘Dev’ to the ‘Ops’ and vice versa.
Find out how to set this up in 30 minutes yourselves.